This article originally posted at http://engineering.conversantmedia.com/2015/08/24/using-kafka-to-distribute-and-dual-load-timeseries-data/

At Conversant, we love OpenTSDB.
Operations teams, software engineers, data scientists, QA, and even some on the business side scrutinize these colorful graphs daily. OpenTSDB allows us to effectively visualize the various metrics collected from our hundreds of servers across several data centers.
Numerous home-grown scripts have been developed to mine the data for engineering reports, alerting and quality through the RESTful API. We screen-scrape the PNGs for internal dashboards. More recently OpenTSDB has taken on the task of looping some of this data back into the production chain (much to the chagrin of engineering management working to replace this bit!).
Once a pet-project, a closely-guarded engineering-only tool, it has since grown into a respectable dozen-node cluster with strong HA SLAs persisting over 550 million data points per day.
Room for Improvement
 Last year we set out to perform a major upgrade of the cluster. Load balancing was introduced (via HAProxy) and an external CNAME created to provide some measure of indirection and flexibility. The original hope was to build a brand new cluster from scratch and port the historical data over.
Last year we set out to perform a major upgrade of the cluster. Load balancing was introduced (via HAProxy) and an external CNAME created to provide some measure of indirection and flexibility. The original hope was to build a brand new cluster from scratch and port the historical data over.
Unfortunately this wasn’t practical – it would take several days to copy the data and there was no easy way of back-filling the missed events once the initial copy had completed. Instead we opted to take the cluster down to upgrade the Hadoop stack (an older version that didn’t support rolling upgrades), and left the OS upgrade for later.
The nature of the metrics collection scripts – a loose assemblage of python and bash scripts – meant that ALL metrics collection would cease during this planned outage. The collection scripts would of course continue to run, but the events would simply be dropped on the floor when the cluster wasn’t available to persist them.
This was clearly less than ideal and an obvious candidate for enhancement.
Conversant needed a solution that would enable taking the cluster down for maintenance while continuing to buffer incoming events so they could be applied when work was complete. Additionally, I wanted to build a backup system for DR purposes and for A/B testing upgrades, or potential performance or stability enhancements at scale. A secondary instance would also be useful for protecting the primary cluster from “rogue” users making expensive requests while engineering is doing troubleshooting. The primary cluster would be kept “private” while the backup was exposed to a wider audience.
A Use Case for Kafka
 This seemed like a perfect use for Kafka – a distributed, durable, message queue/pub-sub system. In fact, this specific issue brought to mind an article I’d read a few months back on O’Reilly’s Radar blog by Gwen Shapira. In the article, Shapira discusses the benefits of inserting Kafka into data pipelines to enable things like double loading data for testing and validating different databases and models.
This seemed like a perfect use for Kafka – a distributed, durable, message queue/pub-sub system. In fact, this specific issue brought to mind an article I’d read a few months back on O’Reilly’s Radar blog by Gwen Shapira. In the article, Shapira discusses the benefits of inserting Kafka into data pipelines to enable things like double loading data for testing and validating different databases and models.
Kafka could be inserted into the flow – sending all metrics into Kafka where they would be buffered for consumption by the OpenTSDB cluster. Most of the time this would function in near-realtime with the cluster consuming the events nearly as fast as they are produced.
However, should the cluster become unavailable for any reason, Kafka will happily continue to buffer them until service is restored. In addition, a separate backup cluster could be built and concurrently loaded by consuming the same event stream. In fact, nothing would prevent us from setting up separate kafka topics for each component of the stack enabling selective consumption of subsets of the metrics by alternative systems.
The Conversant data team has been working with Apache Kafka since late last year, delivering and administering two production clusters. The largest of these handles billions of log records every day and has proven to be rock solid. There was no doubt the cluster could broker metric data reliably.
Simple topic/key design
The initial plan was to publish the TSDB put commands from the current scripts directly into kafka via the kafka-console-producer. Though the easiest and fastest way to prove this out, it would negate some of the benefits of the abstraction.
A simple design was devised instead for a set of topics and keys to represent the metrics. Each component in the stack pushes to a separate component-specific topic. The metric name is used as the key for each message. The message payload is essentially everything else: the timestamp, tags, and metric value. For now these are left as the bare strings. A future enhancement may include packing these into a custom protocol buffers object or JSON structure.
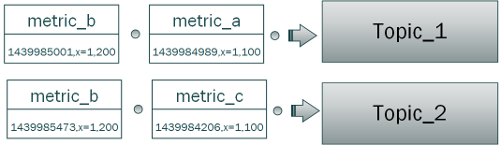
Future
By introducing HBase-level Snappy compression on the tsdb table, implementing a more practical TTL of 2 years, and performing a major compaction, there’s more than enough room to make it possible to split the single cluster into a separate primary and secondary. Other groups are already interested in tapping into this stream – either directly from Kafka or through the new “public” OpenTSDB service. Work on standardizing the metric collection and publishing process code will start soon, providing a more maintainable codebase to support future enhancements and growth. There’s even a possibility of tapping into the Kafka event streams directly using a custom consumer for things like monitoring for discrete critical events.
This new architecture provides greater flexibility, availability, and redundancy. At Conversant, we love OpenTSDB + Kafka.

